
Platform Overview and Purpose
Athlemetrics is a football analytics platform designed for fans, analysts, scouts, coaches, and club executives. Our core objective is to “enhance player understanding from the most fundamental numerical perspective.” Built on real match data, the platform revolves around three core models—Player Rating, Tactical Role Analysis, and Player Similarity—forming a reproducible, interpretable, and extensible analytical framework. Each model adheres to a unified data governance and modeling pipeline: raw data ingestion and validation, feature engineering and standardization, model training and verification, and visualization and explanation. This article systematically introduces the motivation, methodology, current results, and short- and long-term research roadmap for the three modules.
Module One: Player Rating — Multidimensional Scoring Based on Performance Data
Why it matters:
Public and media narratives often shape football evaluations. Even professional teams struggle when data definitions differ across sources. We standardize all values to per-90 and build a transparent rating framework grounded in objective metrics. This approach turns abstract ideas—like creativity or defensive work—into measurable and comparable outputs.
Data coverage:
Our Player Rating module analyzes 30,000+ players from the Big Five European leagues. Key indicators include minutes, goals, assists, passing metrics, key passes, shots, interceptions, duels, and fouls. We convert all metrics to per-90, remove outliers, and standardize distributions to avoid distortion from single-match spikes. To ensure fairness, we interpret scores with positional and tactical role context.
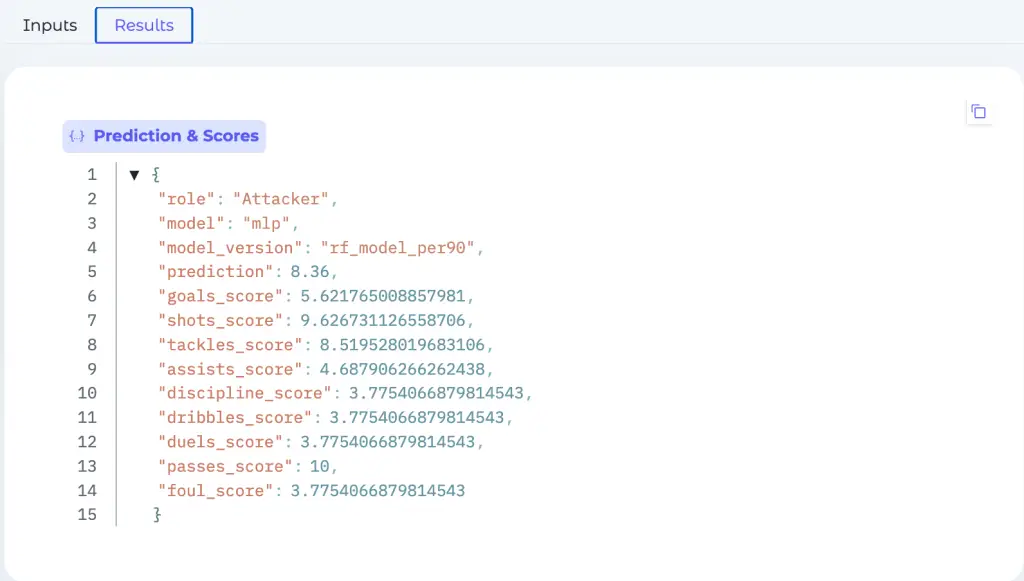
Modeling approach (MLP-Attacker):
The attacker model uses a multilayer perceptron (MLP) to learn nonlinear relationships in high-dimensional data. Standardized inputs feed into hidden layers that extract latent structure, and the output layer produces multiple rating dimensions (e.g., creativity, attacking threat, defensive effort, overall impact). Deep learning uncovers interaction effects—such as how shot frequency, accuracy, touch zones, and pass quality combine in a profile. We apply regularization, early stopping, and directional checks to maintain both robustness and interpretability.
Example and interpretation:
In a demo, high shot volume and accuracy pushed the model toward a “shot-oriented striker” profile, not a pure poacher. Raising creative passing features to extreme values yielded near-maximum creativity (pass_score ≈ 10). These stress tests show the model rewards meaningful performance drivers, not random noise, and responds consistently across dimensions.
Module Two: Tactical Role Analysis — Using Clustering to Describe Roles
Why it matters: Coaches and clubs often ask, “Which role best suits this player?” Roles are not job titles—they are behavioral profiles in data. We use unsupervised learning to derive “role archetypes” from multi‑dimensional statistics, helping decision‑makers achieve faster, more consistent personnel placement.
Data scale and feature matrix: The role module currently covers 11,000+ players and 150+ features. Beyond base stats, it includes xG, shot accuracy, goal contribution, progression and organization, passing distribution, pressure resistance, and set‑piece involvement, among others. All features are standardized and examined for correlation to improve clustering stability and separability. Missing data and league‑specific biases are handled with careful imputation and normalization.
Method ensemble and decision logic: We combine K‑Means, GMM, and HDBSCAN: K‑Means provides clear prototype partitions, GMM captures soft boundaries and mixture distributions, and HDBSCAN is more robust to density differences and noise. Cross‑model label consistency is used for validation; when models disagree, we introduce a human‑in‑the‑loop verification and a rules‑based explanation layer to avoid over‑reliance on any single algorithm. This ensemble approach yields role tags that are both data‑driven and defensible.
Case study: Martin Agirregabiria (2018, La Liga, DF):
- K‑Means / GMM: Balanced Defender
- HDBSCAN: Crossing Fullback
Synthesizing multi‑source labels and feature profiles, we classify him as a “defense‑first fullback with forward runs and crossing capability.” This conclusion aligns with his progression, organization, and passing distribution metrics. The combination illustrates how role context can refine a seemingly generic tag into actionable tactical insight.
Early contribution: The module turns “where a player best fits” from experiential description into data‑backed evidence, aiding training assignments, recruitment matching, and role substitution. For positions with overlapping responsibilities (e.g., fullback, winger, central midfielder), clustering results significantly reduce trial‑and‑error time and improve squad‑building coherence.

Module Three: Player Similarity — Using UMAP to Find Style Neighbors
Why it matters: When a team must replace a core player, the real question is not “same position,” but “similar style.” Built on the role module, our similarity analysis projects high‑dimensional features with UMAP into a two‑dimensional embedding, enabling fast retrieval of “style‑neighbor” player sets.
Method and application: In the standardized 150+ dimensional feature space, UMAP‑X and UMAP‑Y produce an embedding that preserves local structure. Within this space, we can: shortlist replacements, discover younger players on similar growth paths, and identify undervalued players who closely match an existing tactical system. Practical workflows include k‑NN style retrieval in the embedding space and filters for league context and budget constraints. To improve trust in results, we plan to incorporate a “style stability” weight that down‑weights one‑off hot streaks and transient spikes.
Data Scope, Known Limitations, and Quality Control
The current version focuses on the Big Five European leagues with some coverage of other European competitions. For robustness, we temporarily analyze players aged ~17–18 and above with at least ≥700 minutes in a single season. This limits near‑term applicability to youth squads and deep rotation players. To mitigate these constraints, we follow three quality strategies:
- Continuously expand league coverage and age‑range structure.
- Introduce rolling seasonal windows and career‑stage stratification to reduce small‑sample and phase volatility.
- Build cross‑season stability evaluation to track the evolution of player style and efficiency.
Additionally, we monitor representation shifts across leagues, handle missing values consistently, and document feature provenance for reproducibility.
Research Plan: Short‑Term Goals and Future Roadmap
Short‑term goals (1–2 release cycles):
- Expand sample dimensions and data freshness with more leagues and seasons.
- Optimize Player Rating feature sets and loss functions; introduce position‑specific scoring heads.
- Improve multi‑model consistency metrics and conflict‑resolution strategies in Tactical Roles to enhance label interpretability.
- Add “style stability” weighting to the similarity module to dampen one‑off highlights affecting retrieval outcomes.
Where feasible, we will also run calibration across seasons and maintain transparent validation reports.
Mid‑ to long‑term directions:
- Integrate tracking‑type data (running, pressing, receiving, spatial occupation) and event‑sequence modeling.
- Build customized sample thresholds and growth‑phase models for U23 and youth teams.
- Add team‑level and formation‑level context features to achieve “player‑tactics‑opponent” three‑layer coupling.
- Advance cross‑season style transfer learning to support predictions of potential development paths and peak windows.
Conclusion
Athlemetrics is not about “just assigning a score,” but about speaking the language of data to deliver verifiable, interpretable portraits of players and tactics. Through Player Rating, Tactical Roles, and Player Similarity, we transform scattered match statistics into structured knowledge, helping users make higher‑quality decisions in recruitment, selection, training, and viewing. As data coverage grows and modeling deepens, we will continue to calibrate methods and boundary conditions, steadily advancing the practice of moving “from numbers to cognition.”