Football Analytics · Model Design
Building Smarter Football Analytics Models: Rating, Role Clustering & Future Directions
How Athlemetrics combines player rating, role clustering and future tracking-based models into a coherent football intelligence pipeline.
Modern football analytics is rapidly evolving—from simple technical statistics to algorithm‑driven intelligent decision‑making. This article presents how Athlemetrics currently leverages three core models—the Player Rating Model, the Player Role Clustering Model, and future data‑driven extensions. We also look at data cleaning, metric design, algorithmic optimization, and how these components integrate to deliver actionable insight.
1. The Core Objective: From Data to Player Performance Insight
The starting point for all models is clear: use quantifiable data to make “player performance” more objective, explainable and comparable. Whether it is a rating model, a clustering model, or planned tracking and injury‑risk modules, the mission remains the same: empower fans, scouts and coaches to better understand real player ability and potential.
2. Current Version: Rating & Role Models Built on Machine Learning
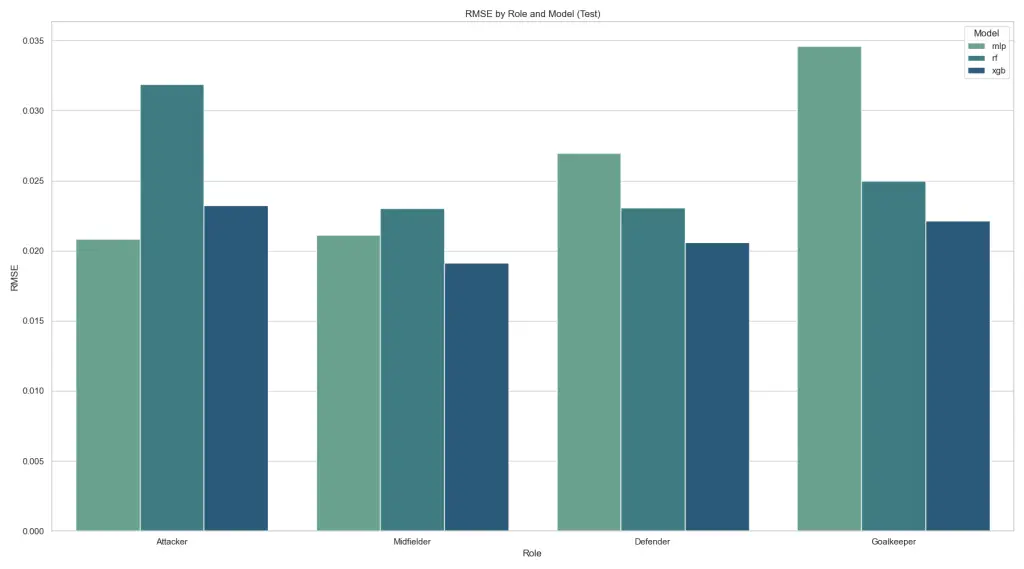
2.1 Player Rating Model (MLP / Random Forest / XGBoost)
Our player rating model uses several machine learning algorithms—MLP, RandomForestRegressor and XGBoost. Similar academic work, such as Wolf et al.’s A football player rating system , expands Elo‑style approaches across 16 European leagues and more than 12,000 players. Bhatnagar et al.’s Rating Prediction of Football Players using Machine Learning presents a multi‑algorithm framework for prediction. These studies informed our feature engineering and algorithm choices.
2.2 Player Role Clustering (KMeans / GMM / DBSCAN / UMAP)
For role clustering we deploy unsupervised algorithms like KMeans, GMM and DBSCAN, combined with UMAP for dimensionality reduction. This allows us to move beyond traditional position labels (forward, midfield, defender, goalkeeper) and to identify styles such as “pressing winger”, “creative #10”, or “overlapping full‑back”. Data‑driven visual methods like player radars are also widely discussed in analytics communities, for example in this StatsBomb‑inspired radar tutorial .
3. Data Sources & Cleaning: From Raw Stats to Usable Features
Athlemetrics currently draws from public statistical sites like FBref (a major source of match and player data), as well as community and industry resources such as McKay Johns’ article Where to get free football data .
3.1 Data Cleaning Steps
Before modeling, data is rigorously cleaned: null values are removed, players with fewer than 700 minutes are filtered out, statistics are normalized to “per 90” or “per season” formats, and inconsistencies in formatting are fixed. This creates a stable foundation for both supervised and unsupervised models.
3.2 Key Metric Framework
We build a metric system across three core domains:
- Offensive Efficiency: shot conversion rate, progressive passes, chance creation.
- Defensive Efficiency: tackle success, duel intensity, interception efficiency.
- Creativity & Playmaking: assist share, build‑up involvement, possession retention.
These metrics are standardized via PCA and weighted using a Critic‑style method before feeding into our rating and clustering systems.
4. Rating Model Enhancements: Moving from External Ratings to Deep Learning
Our current rating targets often stem from external sources like WhoScored or community ratings, which introduces bias. Comparative research shows significant variation across rating systems such as WhoScored and FotMob, as illustrated in this study on football rating systems .
The next step is to move toward fully data‑driven targets: deep learning‑based rating systems that no longer depend on external ratings, instead learning directly from event streams, time‑series patterns and context; and reinforcement‑learning‑style frameworks that estimate player contribution in different match scenarios (high press, risky pass, counter‑attack and more).
5. Future Models: From Tracking Data to Tactical Style Analytics
Next‑generation models we are exploring include:
- Player Tracking Trajectory Models – modelling off‑ball movement patterns, coverage heat‑maps and optimized attacking routes based on tracking data.
- Injury & Load‑Risk Prediction Models – using match density, physical load and opponent intensity to estimate injury likelihood. This domain is gaining traction in sports injury prediction research .
- Tactical Style & Team Fit Models – automatically identifying team styles (possession‑based, press‑heavy, fast counter) and matching players accordingly, giving clubs more structured, data‑driven recruitment tools.
6. What Contributors Can Do (Research & Community)
For academics:
- Test different clustering algorithms for player‑role recognition.
- Compare metric frameworks (e.g., PCA vs. AutoEncoder‑based representations).
- Investigate model interpretability and explainable ML for football use‑cases.
For fans, scouts and coaches:
- Quickly identify player styles and comparable peers using role clusters.
- Apply insights to youth scouting, transfers or tactical alignment.
- Download Kaggle‑ready datasets for offline exploration and custom analysis.
Conclusion: Building the Next Generation Football Intelligence Platform
Athlemetrics’ aim is not simply “presenting data” but building a stable, transparent and scalable Football Intelligence Platform. By combining robust data sources (for example FBref), established academic research (such as Wolf et al. and Bhatnagar et al.) and modern machine learning, we move closer to truly data‑driven football decision‑making.
If you would like to dive deeper into football data collection, model design and role‑based evaluation, we recommend: